What's the big deal about databases?
Databases are simply a structured (or semi-structured) way to record information. Though you might not realize it, you interact with databases every day. Your identification card has a number tied to a government database, you likely have a school or employee number, you have a patient number at your doctor, you have a twitter ID. You have an account number at the bank, and transaction number. You have order numbers from Amazon. Basically, any time you see a number that isn't money, it's a field that someone uses in their database. Even phone numbers!
Before computers, this consisted of things like indexed card files. With the invention of computers came flat-files, where all information was stored on one line, and the computer had to know exactly how long each field would be. In 1970, relational databases were invented, and in 1979 spreadsheets became available. While there are many other newer kinds of databases, relationational databases remain the most popular.
What makes a database relational?
Relational databases are made up of tables. Each row (called a record) on a table has a unique identifier, called a key. This key can be listed in another table to form a relationship between the two tables, which is why they are called relational databases.
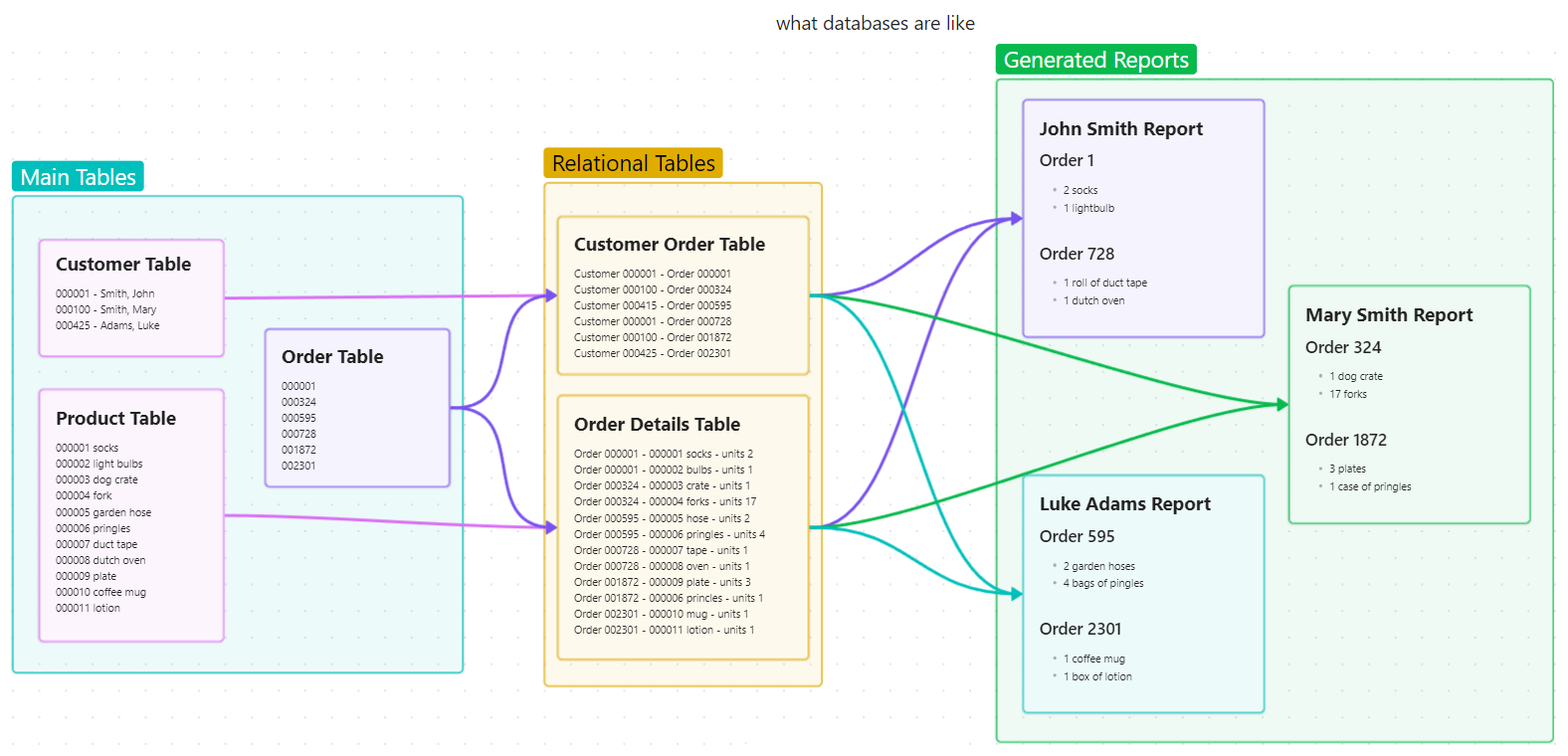
However, the tables you think you'll see in a database probably don't reflect what's actually there. For example, when you imagine a table that might exist at Amazon, many people often thing that there must be their customer number, then their different order numbers, and under each order number will be the barcodes of the products they purchased.

But this isn't the case at all! If it were, Amazon would need millions of tables! What you're imaging is actually a type of "report" produced by linking different tables together using their relationships.
Instead, amazon will have one table that's just a giant list of customers, ordered by their user id number. Then, it will have a list of orders, listed by their order numbers. It will then have an intermediat or relational table that lists user id numbers on one side, and order ids on the other, so that they know who each order belongs to. Then, there will be a table full of products organized by their numbers, and a relational table that lists the order number on one side and the product IDs on the other.
What different kinds of structures can a Relational Database use?
Generally speaking, there are really only two common ways to structure the tables in a relational database: the star schema and the snowflake schema. Star schemas have a central "fact" table, with other tables clusering around it. Snowflake schemas are highly normalized and create a kind of snowflake shape.
What is normalization?
Normalization is a way to make sure that when you delete records you don't accidentally lose information about another topic, that when you add records you don't introduce incorrectly formatted data (misspellings), and that when you update information it will update everywhere. We do this by breaking things into as many tables as is reasonable for our application: that is, when accuracy is extremely important, data is heavily normalized. When speed is extremely important, we aim for as little normalization as we can, without compromising our data integrity.
Let's say, for example, you have a table, and one of the attributes (columns of the table) is "pets", and it is a text field, where you can note the names and types of pets, as many or as few as exist. This data is not normalized because there could be more than one value in the pet field.
If we take that pet field and instead create a table with pets, have a text field to describe their type (cat, dog, etc) and use a foreign key to link them back to their owner, then we have 1st degree normalization because each thing is in it's own field.
There are more degrees of normalization than this, but the 1st degree is the most essential. We only want to store one value per field.